Back to Capabilities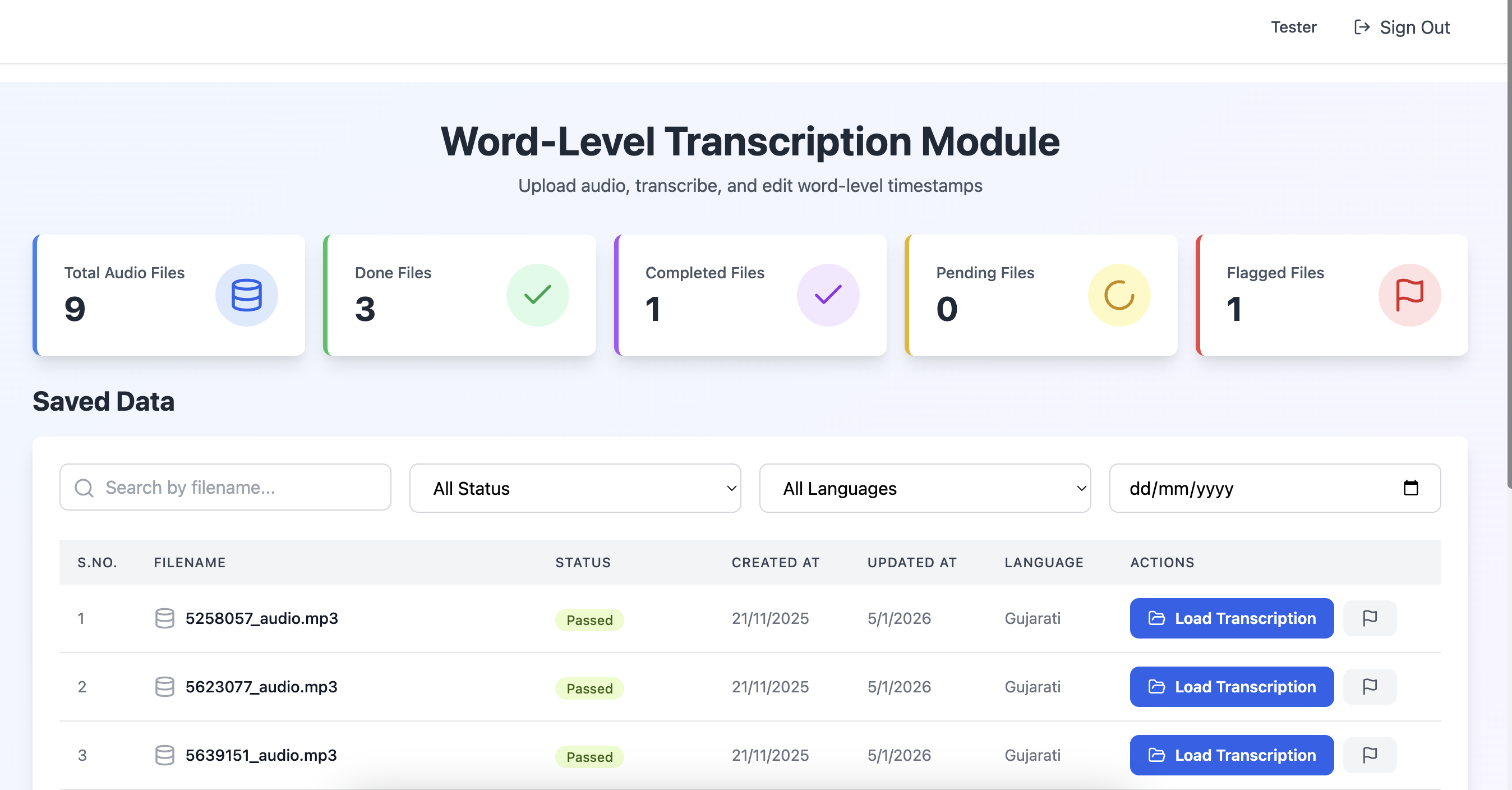
Audio Annotation
Audio Annotation for Audio Models
Structures audio and speech data to power ASR, voice assistants, and acoustic understanding models.
Core Capabilities
- Speaker diarization and turn-taking labels
- Transcription and translation with timestamps
- Acoustic event detection and classification
- Prosody, emotion, and sentiment signal tagging
- Noise profile and background context labeling
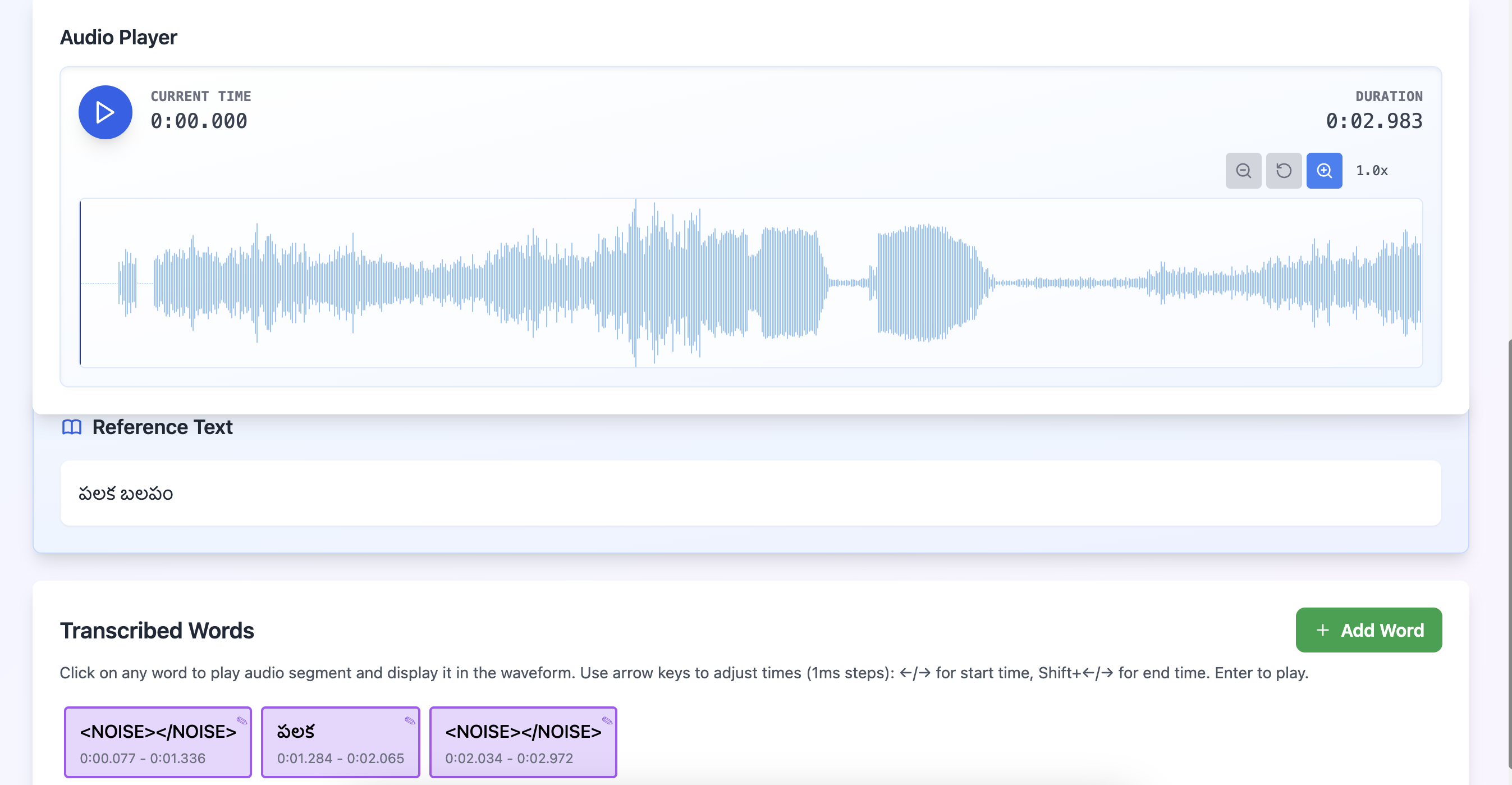
What Clients Get
Clean speech datasets ready for training and evaluation. Rich acoustic metadata that improves ASR and voice understanding.
Why It Matters
Audio annotation unlocks voice interactions and sound intelligence for conversational AI, compliance automation, and acoustic pattern recognition.