Multimodal annotation capabilities built for real-world model training
Flexibench supports deep, configurable, and scalable annotation workflows across Text, Image, Video, and Audio with tooling designed for quality, governance, and model-aligned outputs.
Text Annotation for Language Models
Builds richly labeled language datasets that help models understand meaning, intent, context, and safety constraints.
Core Capabilities
- Named entity extraction and relation mapping
- Intent and sentiment tagging for complex text signals
- Chain-of-thought and reasoning guidance annotations
- Multi-label classification and hierarchical tagging
- OCR validation and structured text extraction
What Clients Get
Model-ready language datasets that reduce ambiguity and improve NLP model accuracy. Fine-tuning corpora aligned to domain semantics and safety policies.
Why Text Annotation Matters
Text annotation shapes how models interpret nuance, disambiguate intent, and reason over language, especially for generative or decision-support applications.
Image Annotation for Vision Models
Teaches vision models to see, segment, classify, and understand visual components with fine-grain detail.

Core Capabilities
- Bounding boxes and object detection tagging
- Polygon/semantic and instance segmentation
- Keypoint and landmark annotation
- Visual attribute labeling (texture, condition, material)
- Complex scene understanding (relationships and context)
What Clients Get
High-fidelity visual datasets for robust model training. Precise segmentation and detection maps for complex vision tasks.
Why Image Annotation Matters
Image annotation is foundational for computer vision models that power analytics, inspection, identity verification, medical imaging, retail insights, and more.
Video Annotation for Temporal Models
Enables models to interpret action, sequence, and temporal behavior across frames, not just static images.
Core Capabilities
- Frame-level classification and tagging
- Object tracking and temporal identity preservation
- Activity and event recognition with timestamps
- Scene segmentation and zone labeling
- Trajectory and motion pattern annotation
What Clients Get
Temporal event datasets that help models learn action dynamics. Behavioral and safety annotations for real-time AI systems.
Why Video Annotation Matters
Video is rich with temporal context. Annotation that captures motion, activity chains, and event sequences boosts model understanding of real-world scenes.
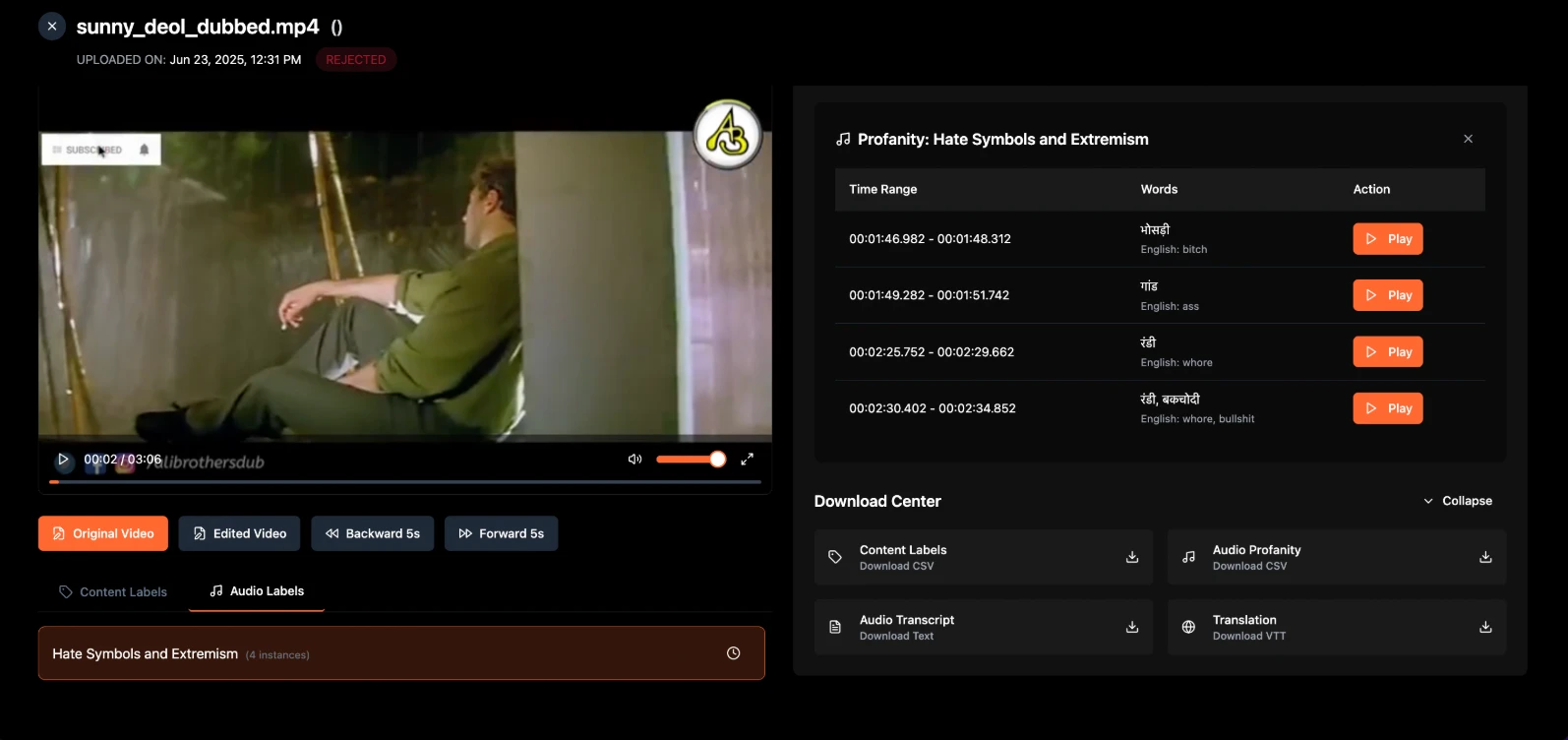
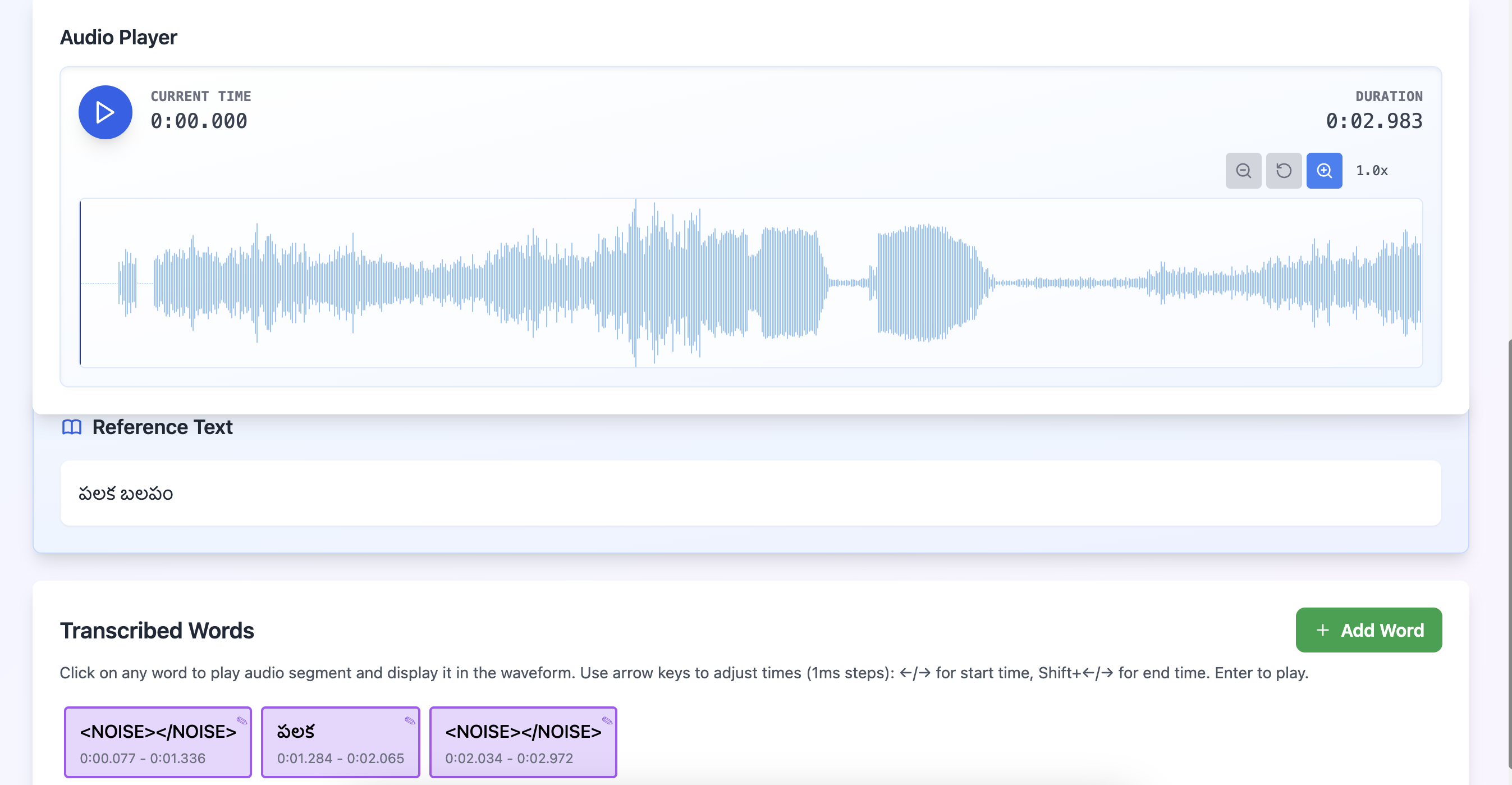
Audio Annotation for Audio Models
Structures audio and speech data to power ASR, voice assistants, and acoustic understanding models.
Core Capabilities
- Speaker diarization and turn-taking labels
- Transcription and translation with timestamps
- Acoustic event detection and classification
- Prosody, emotion, and sentiment signal tagging
- Noise profile and background context labeling
What Clients Get
Clean speech datasets ready for training and evaluation. Rich acoustic metadata that improves ASR and voice understanding.
Why Audio Annotation Matters
Audio annotation unlocks voice interactions and sound intelligence for conversational AI, compliance automation, and acoustic pattern recognition.
Capabilities That Span All Modalities
Powerful features that work seamlessly across Text, Image, Video, and Audio annotation workflows
AI-Assisted Pre-Labeling
Model suggestions speed up human review
Configurable Annotator Workflows
Tailor interfaces per task
Dynamic Taxonomy Support
Reuse ontologies across projects

Quality Control and Review Gates
Multi-tier validation pipelines
Unified Data Management
Consistent datasets for training and deployment
Real-time Collaboration
Seamless team coordination and workflow management
Ready to Transform Your Annotation Workflows?
Start building model-ready datasets with Flexibench's enterprise-grade annotation platform
Get Started